
seleniumを使って、所定の画面まで遷移させ、
beautifulsoupでスクレイピングをしていきます。
環境構築
まずは、スクレイピングをするための環境を作っていきます。
1. Anacondaで環境を作成
Anacondaを開き、Environments > Create
ここでは、Pythonは「3.8」で「scraping」という名前で作成します。
2. 必要なライブラリをインストール
Anacondaの「Open Terminal」より、terminalを開き、以下コマンドで必要なライブラリをインストールする。
$ pip install selenium
$ pip install beautifulsoup4
$ pip install pandasSuccessfully installed 〜 と出ていれば完了です!
それぞれの役割を簡単に説明します 。
selenium
ブラウザ操作を自動化することができ、値のコピーや入力、クリックなどができる。
beautifulsoup
htmlの読み取りができ、タイトルやURLの取得ができる。
pandas
スクレイピングで取得したデータをcsvにまとめるのに使う。
3. ChromeDriverのインストール
Google Chrome のブラウザを操作するためにdriverをインストールします。
- 自分のchromeのバージョンを確認
chromeの右上の・3つ > Help > About Google Chrome
するとVersionが確認できます。 - 同じバージョンのdriverをこちらよりインストールする

このインストールしたdriverの保存先は後ほどコード内でpathを指定するので、わかりやすいところに保存しましょう。
4. VScodeにAnacondaの環境を設定
VScodeのsettingで、「Python: Default Interpreter Path」の部分を、Anacondaで作成した環境名に変更します。
環境のpathは以下より確認が可能
$ conda info -e4. ディレクトリ、ファイルの作成
任意のディレクトリを作成し、pythonファイルを作成します。
ここでは、automation.pyという名前で作成します。
# seleniumライブラリの中のwebdriverモジュールを指定してimportする
from selenium import webdriver
import time
# Chromeを起動する
# browser = webdriver.Chrome(executable_path= 'path名')
# chromedriverが見つかるまでの待ち時間を設定する
browser.implicitly_wait(2)5. ファイルの実行
ファイルを実行します。VScodeでのファイル実行は以下2通りの方法で行えます。
コマンドで実行する場合
実行するファイルのディレクトリ下で以下コマンドを実行
$ python [ファイル名].pyショートカットキーで実行する場合
command + A でコードを全選択したあと、shift + enter
6. エラー解決
seleniumのエラー
上記で作成したファイルを実行の際に、以下のようなエラーとなる場合
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://chromedriver.chromium.org/homeselenium version4より記述の仕方が変わったようで、このようなエラーとなってしまいます。
Serviceを使ってdriverを指定します。
# モジュールの中のクラスを指定してimport
from selenium import webdriver
from selenium.webdriver.chrome import service
import time
# Chromeを起動する
driver_path = '/Users/[user_name]/Desktop/chromedriver'
chrome_service = service.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)
# chromedriverが見つかるまでの待ち時間
driver.implicitly_wait(2)
ここでは、driverはdesktopに保存しています。
これで実行します!
macのシステム環境設定
macの場合、システムにdriverの許可をする必要があり、初回実行時に以下のような警告が出ます。
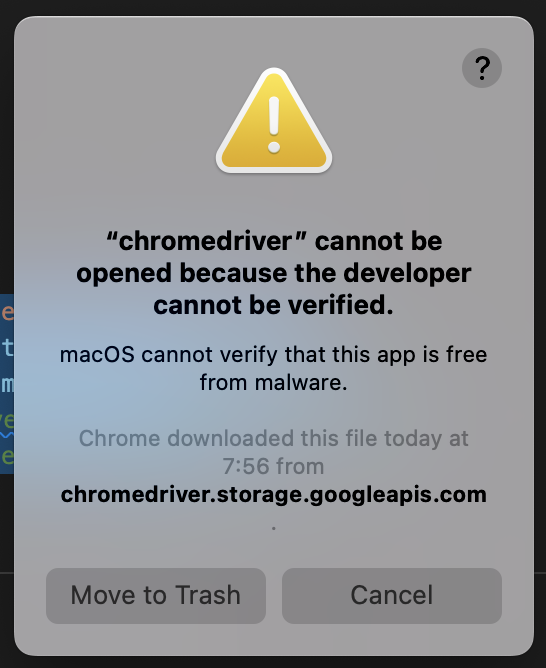
System Preferencesの、「Security & Privacy」の「General」のところを開き、
「Allow Anyway」でchromedriverを開くことを許可します。
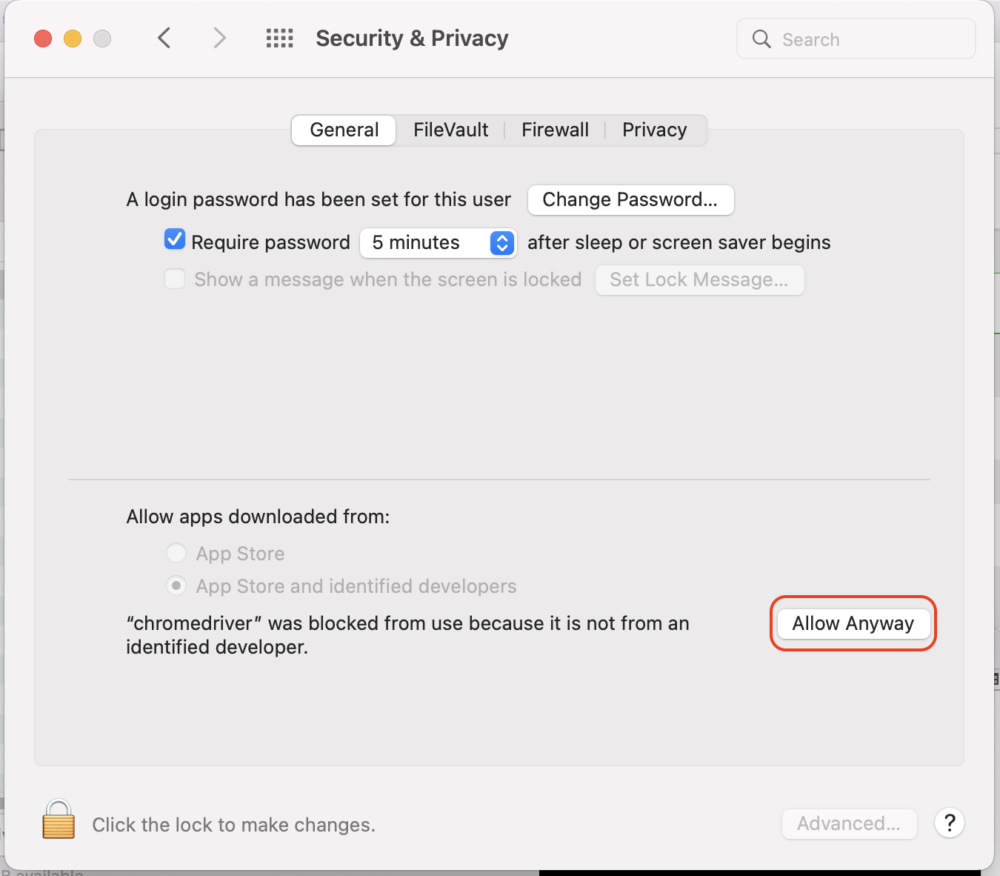
これでもう一度実行すると解消します!
ネーミングによるエラー
cannot import name 'webdriver' from partially initialized module 'selenium' (most likely due to a circular import)ファイル名を「selenium.py」としていたことで、エラーとなりました。
このファイル名は使えないのでご注意を!
7. 環境変数(.env)設定
自動入力の際には、ユーザー名やパスワードを入力するので、誤ってGitHubに上げないよう環境変数設定をしておきましょう!
以下を行います。
python-dotenvをインストール
$ pip install python-dotenv.envファイル作成
現在のディレクトリ下に、.envという名前でファイルを作成します。
テストで書いてみます。
USER_NAME = "test".gitignoreファイル作成
.gitignoreファイルに、.envを記述しgitの対象外とする。
.env呼び出し側ファイル
from dotenv import load_dotenv
import os
load_dotenv()
user_name = os.getenv('USER_NAME')
print(user_name)automation.pyファイルの中から、環境変数に関連するところのみ抽出しています。
ここでは、printで出力し、環境変数が呼び出せていることを確認しました。

環境変数設定は完了です!これで安心してアカウントを使えますね!
seleniumを使用した自動操作
指定ページへアクセス
株探のログイン画面にアクセスします。
url_login = "https://account.kabutan.jp/login?_gl=1*hga624*_ga*MjE2OTIxNzY5LjE2MzI4ODgzMDk.*_ga_T4WG70S1DQ*MTY1MzE4MTY0NS41LjEuMTY1MzE4MTY2My4w"
driver.get(url_login)
time.sleep(2)
print("ログイン画面にアクセス")アクセス後、ログイン後にすぐに次の処理が走らないよう、timeで2sec待ちを入れます。
フォームに値自動入力
前述までの処理で以下画面を開くことができたので、フォームに値を入力します。
それぞれのフォームのidを検証画面より確認します。
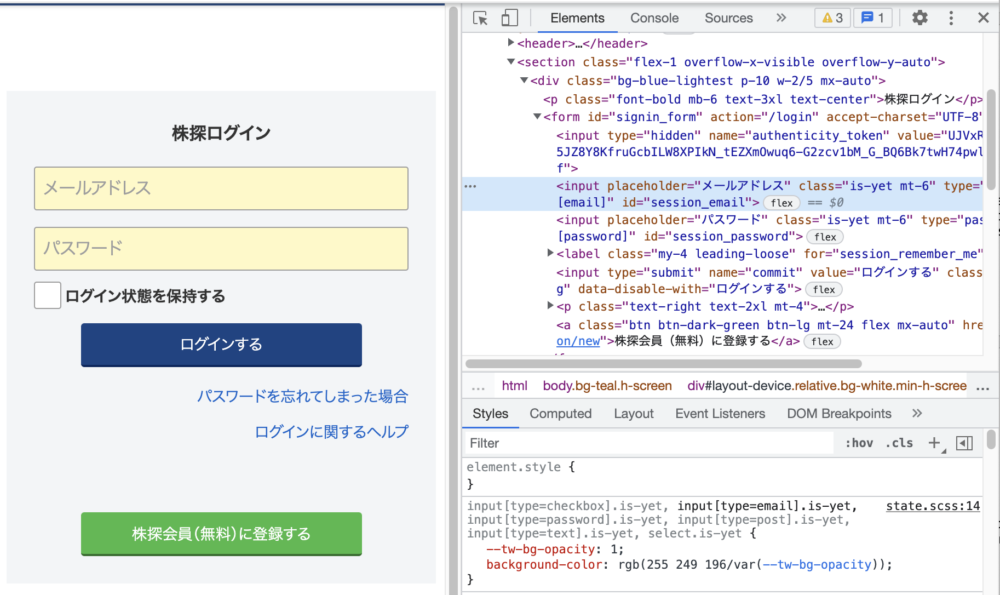
ここで確認できたidを使用します。
user_name = os.getenv('USER_NAME')
password = os.getenv('PASSWORD')
element = driver.find_element_by_id('session_email')
element.clear()
element.send_keys(user_name)
element = driver.find_element_by_id('session_password')
element.clear()
element.send_keys(password)
print('フォームに値を入力完了')フォームに初めから値が入っている場合があるので、予めclearする処理を入れています。
.envに環境変数それぞれの値を設定します。
USER_NAME = "[mail]"
PASSWORD = "[password]"ボタンをクリック
同様に検証画面よりボタンを特定します。
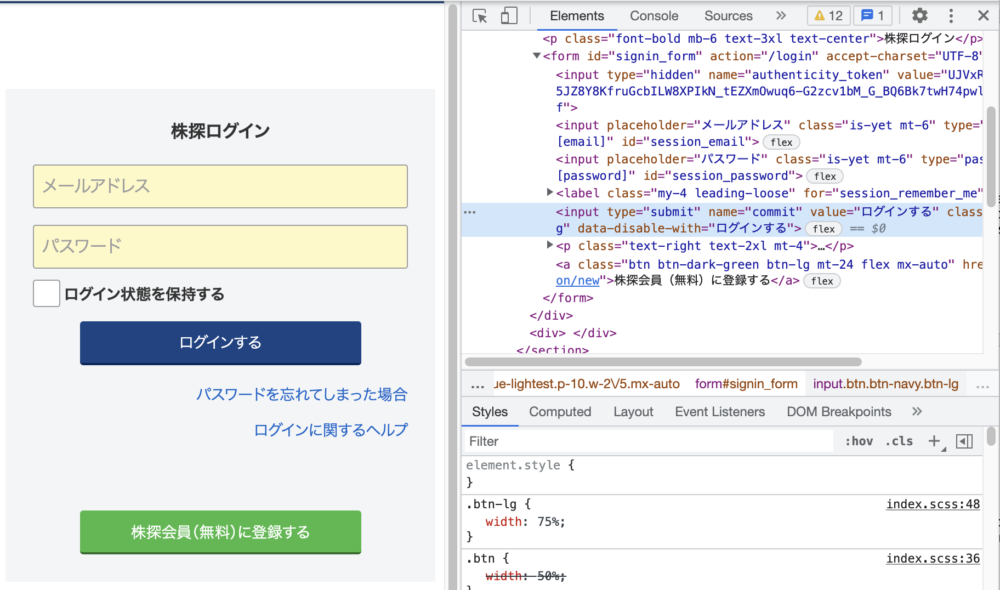
ボタンにはidが無いので、nameを使って要素を指定することにします。
browser_form = driver.find_element_by_name('commit')
time.sleep(2)
browser_form.click()
print("ログインボタンをクリック")ページ遷移
上記までで、ログインができたので、ログイン状態で、ページを遷移します。
url="https://account.kabutan.jp/favorite_stocks"
time.sleep(2)
driver.get(url)
print(url, ":お気に入りページへの遷移完了")以下のようなお気に入りページを表示することができました!
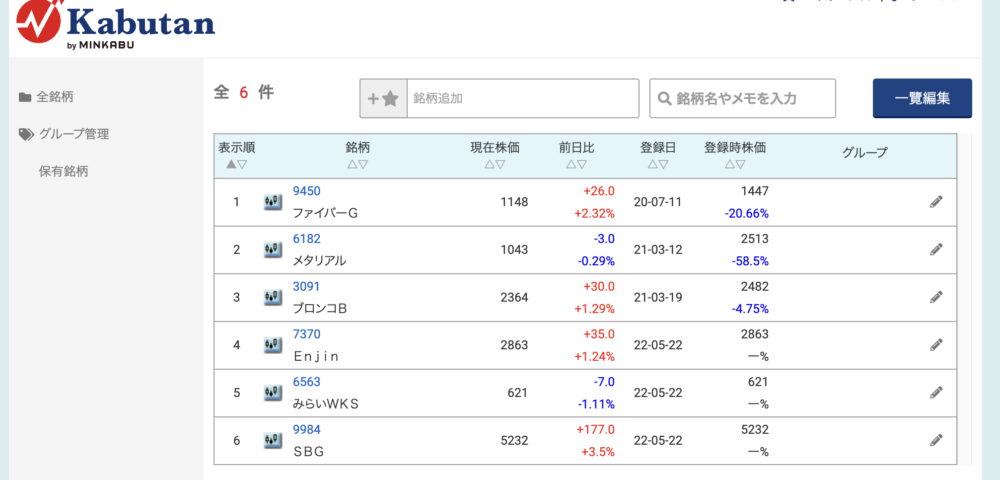
所定のページまで自動で遷移する事ができました。
ここまでを一旦まとめます。
# モジュールの中のクラスを指定してimport
from selenium import webdriver
from selenium.webdriver.chrome import service
import time
from dotenv import load_dotenv
import os
load_dotenv()
# Chromeを起動する
driver_path = '/Users/[user_name]/Desktop/chromedriver'
chrome_service = service.Service(executable_path=driver_path)
driver = webdriver.Chrome(service=chrome_service)
# chromedriverが見つかるまでの待ち時間
driver.implicitly_wait(2)
user_name = os.getenv('USER_NAME')
password = os.getenv('PASSWORD')
# ログインページ
url_login = "https://account.kabutan.jp/login?_gl=1*hga624*_ga*MjE2OTIxNzY5LjE2MzI4ODgzMDk.*_ga_T4WG70S1DQ*MTY1MzE4MTY0NS41LjEuMTY1MzE4MTY2My4w"
driver.get(url_login)
time.sleep(2)
print("ログイン画面にアクセス")
# フォーム入力
element = driver.find_element_by_id('session_email')
element.clear()
element.send_keys(user_name)
element = driver.find_element_by_id('session_password')
element.clear()
element.send_keys(password)
print('フォームに値を入力完了')
# ログインボタンをクリック
browser_form = driver.find_element_by_name('commit')
time.sleep(2)
browser_form.click()
print("ログインボタンをクリック")
# ページ遷移
url="https://account.kabutan.jp/favorite_stocks"
time.sleep(2)
driver.get(url)
print(url, ":お気に入りページへの遷移完了")ここからスクレイピングをしていきましょう!
最終的には、先程遷移したお気に入り画面の情報をcsvにエクスポートします。
beautifulsoupを使ったスクレイピング
beautifulsoupを使ったスクレイピングの手順はこうだ!
- html.parserを使って、htmlを解析して取得する。
- prettifyを使って取得したhtmlを整形する。
- htm要素を指定して値を取得する。
ファイル作成
ここでは、scraping.pyという名前でファイルを作成します。
ログイン後のページよりhtmlを取得
ログイン後の現在のページをdriverのpage_sourceから取得し、BeautifulSoupに読み込ませます。
from bs4 import BeautifulSoup
import urllib.request as req
page_source = driver.page_source
parse_html = BeautifulSoup(page_source, "html.parser")
urllibは、URLを扱うためのライブラリです。
要素の値を取得
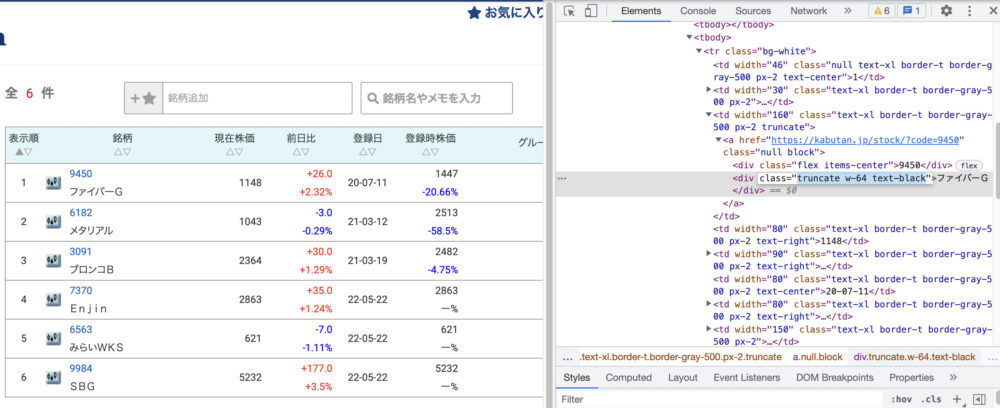
ここでは銘柄名を取得します。
name = parse_html.find_all('div', class_="truncate w-64 text-black")
name_list = []
for n in name:
name_list.append(n.string)
# appendは要素を追加するメソッド。pushと同じ
print(name_list)
class名を検証画面より取得し、お気に入り登録している企業を全て取り出し、文字だけにし、name_listの形で取り出しています。
class名は以下のように確認します。
こちらを実行すると、以下の結果となります。
['ファイバーG', 'メタリアル', 'ブロンコB', 'Enjin', 'みらいWKS', 'SBG']スクレイピングをすることができました!
あとは、自分の取得したいデータに応用していけば自分だけのデータ収集ができるようになります。
以上、お読みいただきありがとうございました。
コメント